





I’ve made a conscious decision to differentiate between two types of event data in real-time analytics architectures. In this (quite long) post, I share with you my reasons for doing so, and pose a question: are we limiting the benefits of Event data?
Wherein I learn about Event data
In 2019 I joined Imply, a company powered by and powering an open-source database called Apache Druid®. This database munches up event data like a hungry hippo, and delivers on our decades-old promise of democratised real-time analytics.
Joining this fast-paced Silicon Valley start-up as a field engineer, I had to do some brain rewiring. Coming from a world of Microsoft SQL Server Data Warehouse and Oracle Forms 6 - and yes even Ingres - I had to think differently about how data represents business and what Druid’s foundations in data arriving at scale, resolution, and speed meant for people in IRL.
Conclusion: Event data is cool
I don’t profess to be a professor of Event data. I am not, unfortunately, a Time Lord. So when I joined Imply, there was a single enterprise architect-type curiosity: “What the hell is an event?!”
On to the RADStack paper, written by members of the Apache Druid development team, to find their definition:
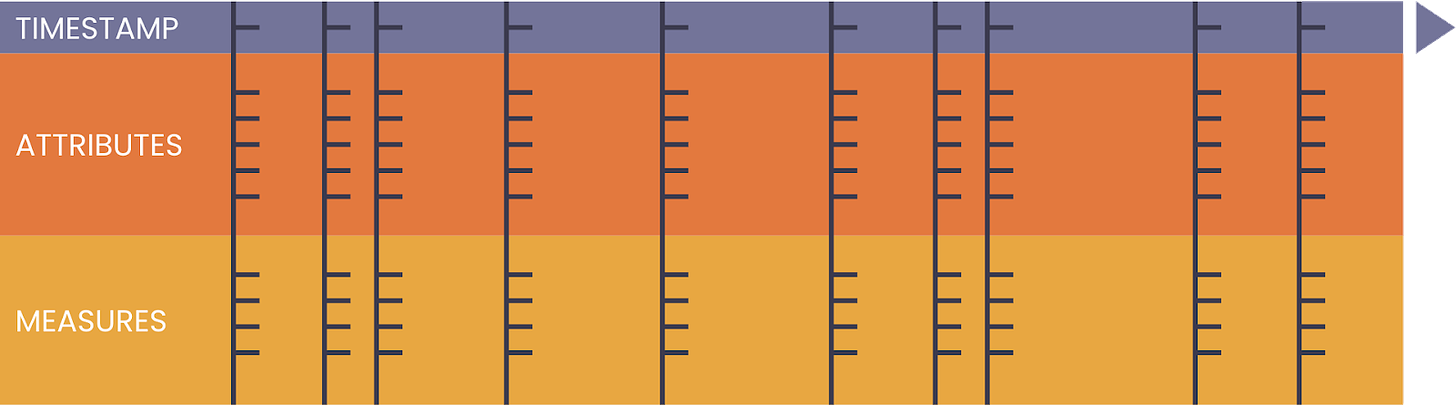
“Each event is comprised of three components: a timestamp indicating when the event occurred; a set of dimensions indicating various attributes about the event; and a set of metrics concerning the event.”
“OK,” thinks I, “I get it. This is just time-stamped data recording stuff that happens. It’s the ticks of the clock, not the time itself.” (Oh hello - there’s a soundbite for ya!).
“Wicked. Cool. No worries. Got it.”
Bolstering that, at Virtual Druid Summit, Target’s Jeremy Woelfel filled me with glee when he said:
“If you think about it, everything in business is about time.”
I felt I had joined you all in the real-time analytics world. Like a bad trip, I could see the world made up of observations of things happening, whizzing around me like bees. It could be sensor data - with readings and some kind of location data - and the all-important timestamp. It could be weighbridge measurements of delivery lorries as they go into and out of distribution centres. Clicks on pages as people browse websites. Click-throughs on adverts. Swipes on door entry systems.
I am one with this definition.
Namaste.
As time goes forward, Events contain three families of data useful to end users: analytics on the measures (“metrics”) over time periods (“timestamp”) and attributes (“dimensions”) for deeper analysis through filtering and grouping.
Technically that’s great - but I also learned about the difference it was making in the real world, whether that’s helping people reduce their carbon emissions and electricity bills, analysing bee colony collapse disorder, or protecting the personal data of children.
Wherein I learn Event data isn’t about events
As time has gone on, something has bothered me about an event recording “a timestamp indicating when the event occurred”. When the event occurred. It’s past tense.
That is watermelon cool if your rows record near-instantaneous things. A door shutting. A mouse clicks. A tick-tock.
But what about those things in business that are in no way finished in that period? Like a birthday party, or a dental appointment - any event that isn't about a point in time but more like a series of Events (unfortunate or otherwise).
Whether it’s a sales order or a delivery, the attributes and measures we want to analyse get a little bit more accurate over a longer period.
In fact, if you "just update the row" we decrease our opportunity to learn about events like that - we lose granularity - the story - the nuance.
Revisiting Events
The University of Belfast Sonic Research Centre published a paper handily entitled “What is an event?” that doesn’t use the row-with-a-timestamp-and-attributes-and-measures definition that we’re all used to.
Instead, they look to music, using the concept of an “x-schema” (citing Narayanan) to talk about events:
“X-schemas are parameterized routines with internal state that execute when invoked [and] captures changes in time by the sequence of its states and processes, and in the same sense that time is directional (and irreversible) so is that sequence.”
This definition appeals to my background in business process analysis and, I would suggest, programmers as well. When I use the phrase "X-Event" now, unlike a simple Event we know and love, I'm talking about this exact thing: something that's more like a function that gets called, within which attributes and measures change over time.
In the paper is an example X-Event that goes through five states:
I am getting ready to walk
I’m ready to walk
I’m walking (Progressive)
My walk is coming to an end
I’m done walking (Perfect)
We know that a sales order goes through states - we know that a customer journey on a website goes through states. Life is like this. Words are like this. These are real events and they’re what I’ve started calling “X-Events” (like the Kendall X-Schema) as opposed to “Events” - the former representing data changing because of events, the latter being those “perfect” and “past-tense” events that are closer to the RADStack definition.
Using Events to model X-Events
Confession: I love Business Process Modelling Notation. So here I’ve built a diagram that illustrates the X-Event that Kendall talks about:

It reads, “after some prompt I get ready to walk and then I walk repeatedly for a bit until ... the end”.
What’s the traditional “Event” view of this walk? Well, it’s a single row emitted right at the end - creating a “perfect” Event row (shown here as a Message End Event). This is a safe, cuddly place to be. Everything has settled down in an orderly fashion and all the data created, read, updated, or deleted by the X-Event is in its final state. AWESOME.

But. Unlike the click of a mouse on an advertisement or a packet flying across the network, an X-Event like walking or delivering a parcel or cooking dinner or washing clothes takes time. By limiting our data model and our analytics to perfect representations of the world, we miss one truly valuable opportunity: we can’t understand what it is to be walking.
To do that, we could emit events at each state change (shown as standard and looping Send Tasks, and Message Intermediate Throw Events) and see what things would be like.

Now we have a handy stream of rows, each one with the triad of a timestamp, attributes (state, reference to the person doing the walking) and some metrics (distance they’ve moved). Just like this:
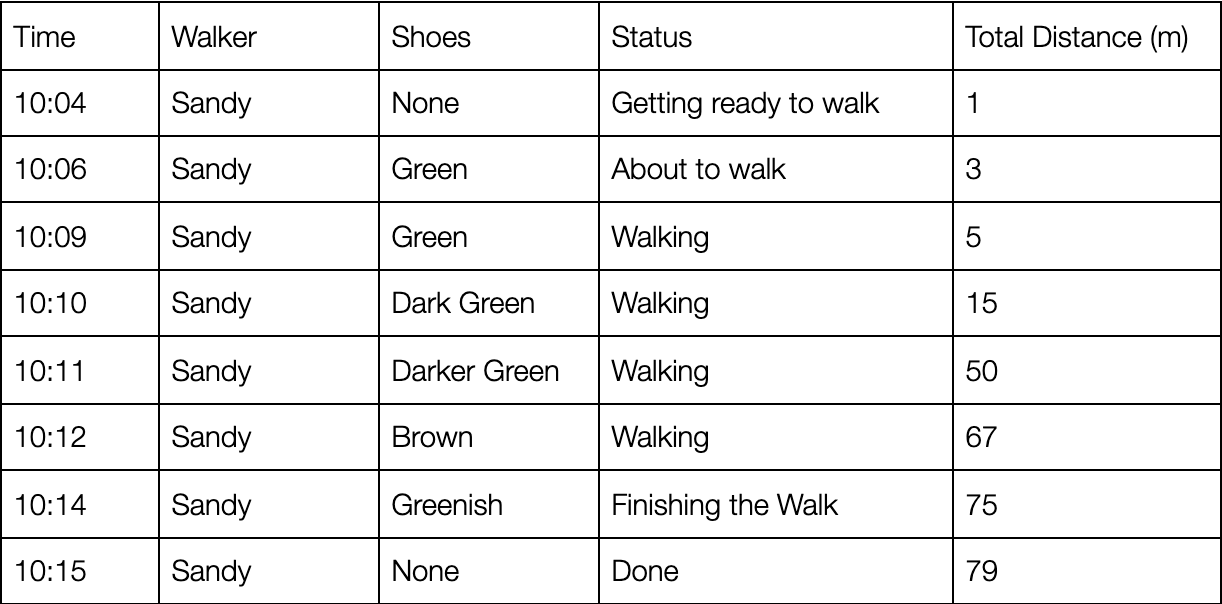
Our timestamp lets us do cool time-based analytics, the Total Distance measure shows Sandy doing some kind of walking while getting ready (maybe putting on their shoes or getting some water) as well as the increased activity while actually walking and - finally - when they take their shoes off and have a shower before they’re done, and we can filter things to do stuff like counting the number of people “Getting ready to walk” without shoes on.
With this kind of data, unlike an UPDATE, I can analyse changes in attributes and measures along the entire X-Event for multiple walkers in real-time. It’s kind of like a slowly changing dimension turned up to 11.
I could ask “who is currently walking?” or “on average, how far have people moved before they’re ready to walk?” or “does the month affect how many people stop their walk after travelling less than 5 metres?” And we could use Theta Sketches for set analysis to ask “who didn’t get as far as walking?”.
In our dreams, what would an X-Events-compatible model be?
X-Event Streams
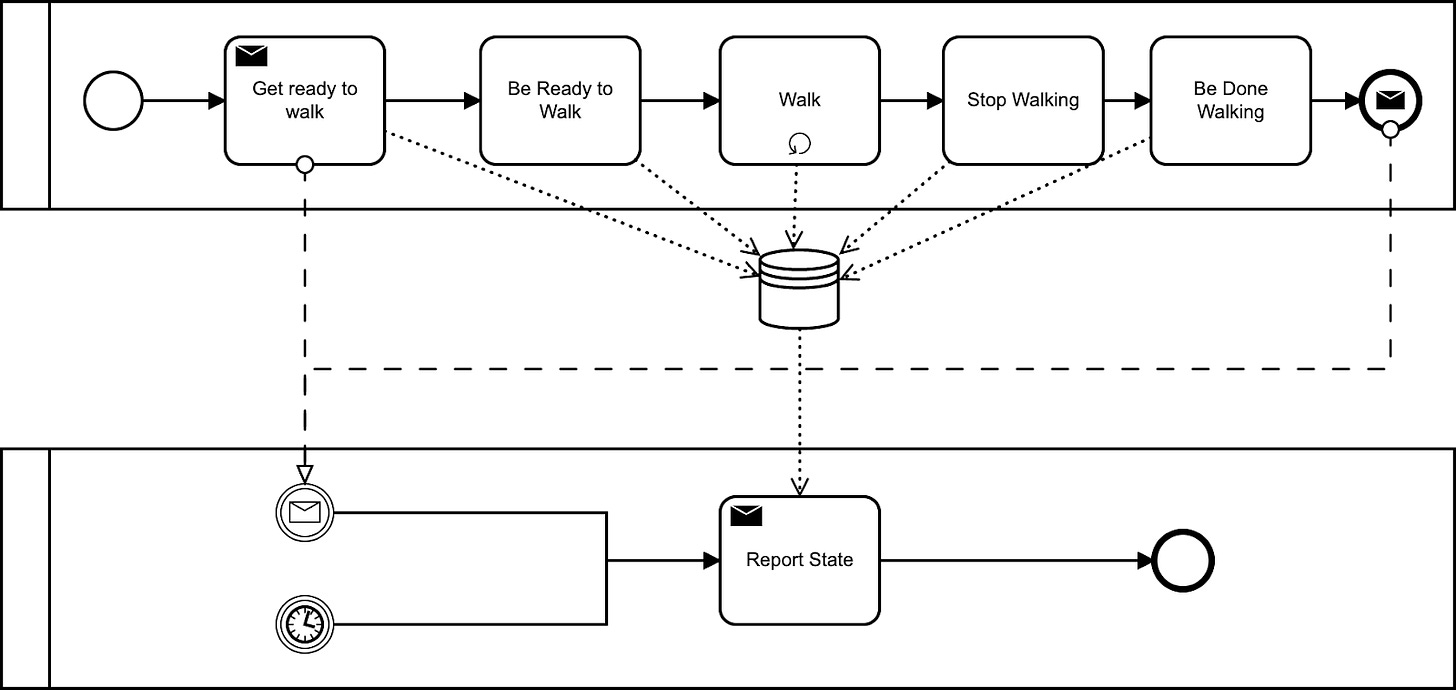
Here’s one idea. In this design, we have Sandy doing a walk. Notice there’s a trigger at the start that kicks off “Report State”, which emits our “past tense” event to the stream - timestamped, and complete with attribute and measure data read from a shared location.
In that Report State you’ll also spot another start condition - this is a simple timer that runs frequently and goes on emitting rows over and over. (That’s not the only option of course - maybe each state could just message the Report State flow…)
We still get our Events, but now we have “glue” - we have something that brings them all together. This is the thing that brings the Events together into a true X-Event. And as Events themselves, they might have a timestamp, attributes, and measures. But this time, to be clear, about walks - not about walking.
X-Event Analytics
In this world of X-Events, what kind of questions would be easier to answer?
We could start with a simple “who goes walking?” But we could really push it. “In London how many people between 30 and 35 have started walking in the last 10 minutes who, last time they walked, finished slower than other people aged between 35 and 40 in Paris did this time last year who were wearing orange shoes?”
OK. Instead of me being mad as usual, let’s look at Narayanan’s thesis. (I’m sure he’s much cleverer than me and probably not as mad!) Here’s what he suggests we could ask questions about:
Cause - what forces changes in state
Purpose - what factors propel things towards their destination
Plan - what routes the subject took to being finished
Acts - the individual movements inside each X-Event
Difficulty - identifying obstacles met along the way
Progress - the schedule from A to B
Goals - consistent and resulting data that indicate why what happened happened
For example, when we want to find out what caused someone to start their journey on your site, we might ask the X-Event itself for the Referrer - it would work out that this means getting the “previous page” from the very first Event recorded in the stream and present that back to us.
And to understand different routes, the X-Event might allow us to leverage funnel analysis on the underlying event data, or give back (oh god I love…) a Graph that we can do all kinds of super cool analysis with.
Or perhaps we would ask the X-Event to identify intermediate actions for us that lead to one outcome versus another - ie, looking for abnormal flows.
I truly believe Druid would be an excellent springboard for X-Event analytics. The in-built columnarisation, compression, and sharding make it excellent for all kinds of time-based analytics and for asking highly complex questions.
At the moment, not only does Druid present limitations, but so do the stream hubs that feed it.
In Druid, where I am most happy, for example, I am not sure we could work out the average distance travelled between the states - say, between Getting Ready To Walk and Finishing The Walk.
And unless we have architectures built to re-write chunks of time as data becomes perfect, we must pick which state we want to analyse. Imagine: if we capture the data when the walk is Done (by filtering in the Druid ingestion spec, for example) it is then too late to find out who is walking right now. And if we wait until people are “getting ready to walk”, we have this quasi-wobbly-bobbly state of knowing nothing about anything really useful about why the person is walking or whether they ever finished their walk.
The end is nigh…
Concluding then, I welcome your comments - I hope I have at least generated more questions than I have answers! But most important of all, is this something that, as an industry, we might put effort into? And if you have solved the X-Event problem, what did you do?
Special thanks to Hellmar Becker, Richard Dobson, Rachel Pedreschi, Matt Sarrel, and Itai Yaffe for their feedback and creativity as I compiled this post.