
start-druid - the new startup script for Apache Druid
Pouring luscious custard atop my Apache Druid Raspberry Pi cluster

What seems like a million years ago now, I wrote a blog post on how I’d used four Raspberry Pi machines to spin up and play with the Apache Druid database. This has worked brilliantly for all the learning I’ve had to do with Druid over the years and to test out new features and write stuff like this! (With the occasional crash during ingestion… he-hem.)
But now, as the Developer Relations team at Imply start to work with the gleaming awesomeness of Druid 26.0, it’s time for an upgrade from Druid 24.0.
And there’s an important new feature for me to consider using: the new Druid startup script, start-druid.
It promises to optimize CPU usage, automatically determine the most efficient memory allocation, and provide me with increased flexibility in getting Druid up and running.
WELL LET ME TELL YOU. I’ve been working with Druid for 8.7 billion years. And there was a lot of pain getting the Pis to work with Druid – limited cores, limited memory, and a lot of calculations on very advanced and colourful spreadsheets to get the JVMs to be stable. How could this script possibly compare to my brilliant brain and complicated spreadsheets?!
Join me on this journey of humility, as we explore how the script transformed my perspective on Druid deployment entirely, and how it revealed to me that, indeed, I cannot perform calculations accurately.
Setting the scene
For those unfamiliar with the old post, I have all the config files and the distro itself in a folder on my Macbook. I then have a shell script that rsync all the things to the /opt folder on each Pi. (Obvs, I wouldn’t do this in a 1500-node production cluster!)
Before I do this, with every upgrade, I diff all the config files, check what I might need to merge (including those awesome JVM calculations) and then `rsync` it all.
echo Master
rsync -azq apache-druid-24.0.0/* ubuntu@druid-master-0.lan:/opt/apache-druid/
echo Data
rsync -azq apache-druid-24.0.0/* ubuntu@druid-data-0.lan:/opt/apache-druid/
rsync -azq apache-druid-24.0.0/* ubuntu@druid-data-1.lan:/opt/apache-druid/
rsync -azq apache-druid-24.0.0/* ubuntu@druid-data-2.lan:/opt/apache-druid/
echo Query
rsync -azq apache-druid-24.0.0/* ubuntu@druid-query-0.lan:/opt/apache-druid
You can see from this script that I’ve got three data Pis, 1 query Pi, and a master. And for each of the processes that run on these boxes, there are associated JVM and runtime.properties files. Each one is precious to me, not unlike a pint of beautiful real ale. Each one contains just the right config for each service – and not just each service, but each service as it runs alongside the other services.
I told you my calculations were beautiful.
RTFM
The first step was for me to check the release notes.
One of the significant changes in 25.0.0 – which I just need to be aware of because of the minuteness of my cluster – is the change from ZK to HTTP for segment discovery and task management. This should reduce the burden on Zookeeper – I’m interested to see what ends up staying in Zookeeper, so I’m gonna come back to that … some day … !
Aside from the other cool things in 26 (like auto-schema detection, UNNEST…), I also spotted support for the EXTEND keyword in INSERT statements (need to look at that…) and better work splits in the MSQ engine that might help when ingesting data into my tiny cluster. I also did quite a lot of modelling work on the Chicago taxi data set, and make use of COALESCE at ingestion time - so I might get a little bit more juice thanks to work on that function. There’s also the promise of better memory utilization though I’m not quite ready for middlemanager-less ingestion quite yet… getting this cluster running with Kubernetes is a job for Sergio Ferragut and I in a future universe!
So, other than functional things, my only concern is on how I get Druid to start, making sure that Java doesn’t explode all over my floor.
Armed with the untarred tarball, it was time to get --help.
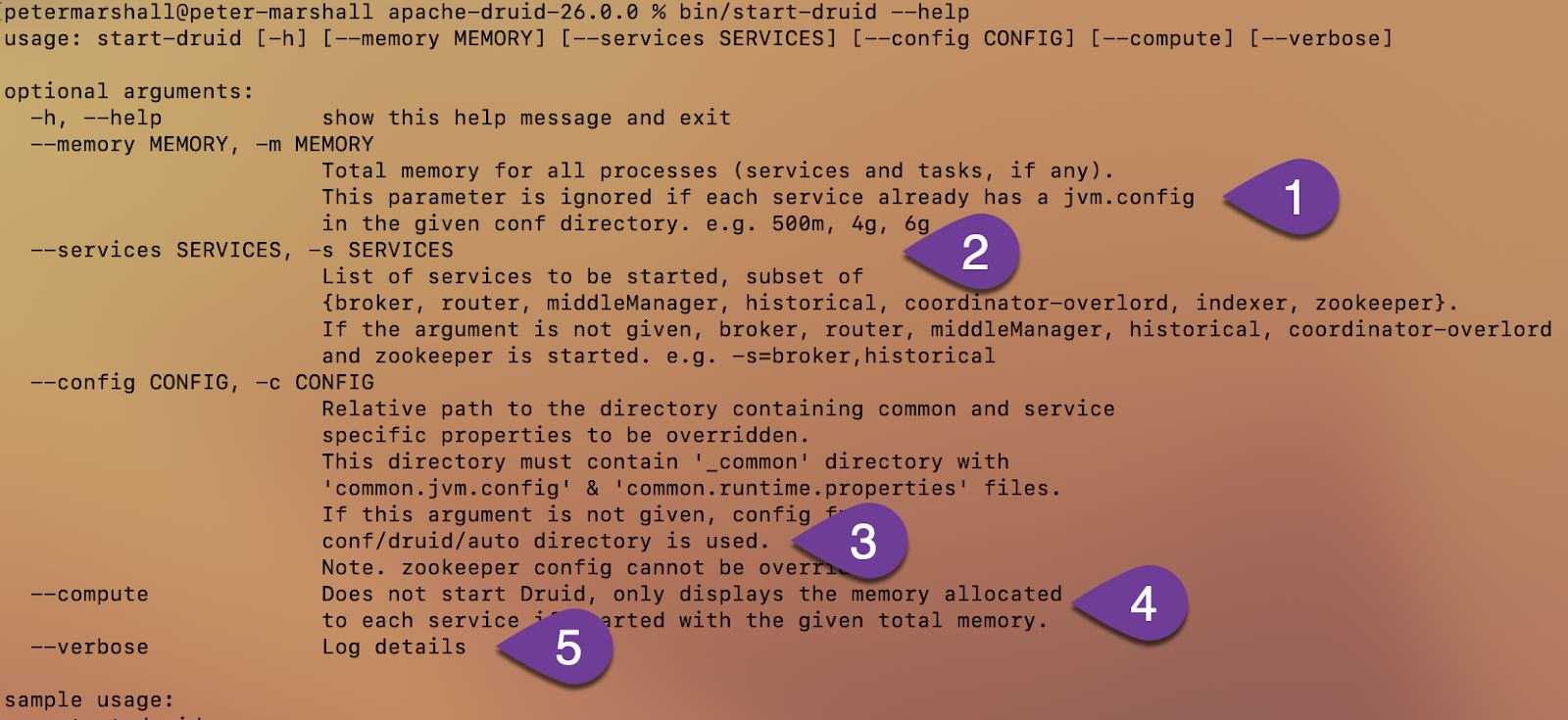
(FYI you can read how the script works by looking at the Python script itself – start-druid-main.py. It’s nice like this cos we can all contribute suggestions to make it better through Github.)
I am going to assume that all I need to do is:
Specify the memory to allocate on the machines (I’ll start with trying 3.5GB),
Specify what services to start – so now I can just one script instead of a billion different ones. The downside is that I now need to remember what the old server startup scripts used to automatically start for me, and do that myself,
Put any cluster-specific configuration into the auto folder in 26,
Check what the script will do re: memory – see whether I was a clever boy when I worked out the memory sizes myself from underneath all those spreadsheets, and
Optionally invoke Ren & Stimpy.
Setting up the “auto” config files
It was time for me to Meld the changes from one distro config folder into “auto” to find out exactly how this script was going change how I configured and deployed Apache Druid.
_common
My first spot: the new common.jvm.config file. This has some basic stuff in it that appears everywhere in all the old JVM files. Like the garbage collection handler. Yawn. What it does prove tho, is that someone really did think about this. I know I don’t need this stuff in my other JVM config files.

For dependencies, I’ve got an Oracle Virtualbox Linux VM in an old dusty Windows box under my desk running min.io (for deep storage), and it also runs MySQL (for the metadata database). And, as expected, in common.runtime.properties, I found the usual suspects:
the extension list (I’m using MySql and Minio’s S3 APIs, so needed to add those),
the Zookeeper location (it’s on that silly linux VM, so I need to change the zk host entry)
Deep storage location (need to add the S3 creds and buckets), and
Task Logs location (more buckets).
I also have a jets3t.properties file in my 24 distro config – that’s for mini.o. Swipe right. Thanks. NEXT.
broker
Note to the unvarnished – this is a new folder - it used to live in query/broker. In fact, so did a lot of the others - once nested under server types - but no more. The nesting into server types has gone.
“BUT WHY?” I screamed to the innocent void. “WHY DOES EVERYTHING HAVE TO CHANGE?!” The answer would come, of course, but this was not yet my time.
I duplicated the repo, added -bananas to the end of the folder, and moved all the config folders around so it made the diff I was doing easier. Hey presto, easier diffs.
Comparing my old jvm.config to the new common.jvm.config, I could see the important difference this startup script promises to make to my life:
Calculating the heaps and direct memory - it is going to do it for me.
I don’t have to worry about updating and distributing these bloody files around any more.

Continuing my journey of increasing trust in the programming prowess of the Druid project’s contributors, I leave the 26.0 version in place… or should I say, left the 24.0 version where it was (remembering the script help monster said that, if I have this file, start-druid will use this instead of doing the calculation itself).
Now the broker’s runtime.properties.

I need to keep in mind that HTTP connection thread pool calculations are important. I may have to come back to this in the future. Druid’s going to use a lot more HTTP now than it did before what with Zookeeper getting to go to bed more often and get some rest. And in a production environment? I would be doing more than accepting the new config file.
Result? No copy forward of my old config.
coordinator-overlord
The only weird thing here is that the runtime.properties used to have druid.indexer.runner.type=remote - and it doesn’t any more. Why, me thinks? Well, a dip into the full configuration reference and I infer (SLASH presume) this is part of the move to using HTTP. Thusly, no copy forward of this config either.
(This is already making me think that future updates of Druid are going to be so much easier…)
Historical
Here, I spotted my calculations again - 1 and 2 below are from my trusty spreadsheet.
/ignore

The segment storage (3)? I need to address that. Druid has a default of 300g, and my Pis only have 256g cards in them. Easy fix. Save. Done.
Finally, (4). Now I recall turning off caching on my little Pis. Why? Because despite the excellent ability Druid has for handling tens of thousands of concurrent queries, there’s only me. And I thought, why don’t I just turn that off – get some memory back? This could be something I come back to – to eke out a little bit more memory – but for now I’m gonna go with the flow and leave it to the auto.
Indexer / Middlemanager
Similar story here tbh with this runtime.properties file – my calculations on the left, auto going on to the right.
Except for one thing – druid.worker.capacity. Worker capacity is what is used to set how many tasks can be spun up by each node to do ingestion (and other things). Our new script indicates that this is calculated automatically. Noting for later – what will this new script do?
Router
Runtime.properties here – HTTP threads again. Again stuff I calculated manually. (Must not forget HTTP connection pool calculations…)
It’s not in the distro…
A quick folder comparison remained – just to check I’m not forgetting anything I’ve added to the standard distro – and that means, particularly, extensions. And for me, that’s the mysql-connector-java extension because I’m using MySql.
Huzzah.
Getting it working
This script already has great promise. If this works, I don’t need to worry about copying anything forward when I do upgrades except for the common.runtime.properties and the extensions. All those custom JVM settings I had to do, calculating workers, working out HTTP settings: maybe I can just let the startup script handle it all.
Next, turn on all that pie. Yummy pie. And start-up that Windows VM for my master and min.io.
While apt does its updateness (just a habit) I run my dist script to push 26 into /opt on the boxes.
Time to RUN.
I am going to have to be more specific about the services to bring up – the old scripts used to just go BLAH and you’d end up with “a query server” or “a master server”. I’m working with this model:
Master (
coordinator-overlord,zookeeper)Query (
router,broker)Data (
middleManager,historical)
Starting with getting a master server up and running, let’s see what the script thinks I’m going to end up with. I’m going to use the cool new --compute flag:

My old config calculation gave the coordinator-overlord 2g of heap - druid-start wants 3276m. Will it fit? Yes! Does this config make better use of the resources available on this Pi? Yes!
The only remaining concern here is Zookeeper. Will it explode? Looking back at the help, there are an important couple of lines:
Note. zookeeper config cannot be overridden.
Config for zookeeper is read from conf/zk.
Taking a look at that config, I’m happy. ZK gets 128m – which is tiny and will fit into the memory without any problems.
Result = started the master!
Now, let’s check out the query server - the next on my list to get going. Below, what I used to have:

The test (bin/start-druid -m=4g -s=router,broker --compute) allocated 256m for the router instead of the 1g before (had I completely overcalculated what I needed? Quite possibly!) plus 128m for the direct memory (same as me). And the script spat out 1812m for the broker - versus my 2g (near enough!) with 1208m direct memory (close enough). Result = 750m-ish returned to the OS.
Running this, though, threw an error – java classes were arguing with one another. But a simple rf -rf * doodah, doodah in the /opt/apache-druid of all my nodes soon sorted that out.
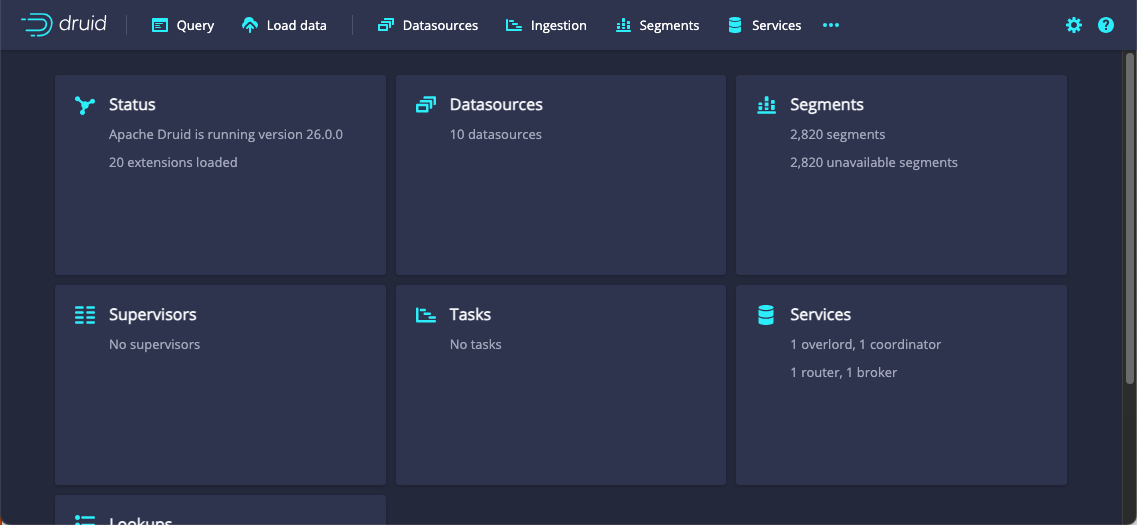
Hurray! A console. And yep, all my segments are still there (with nowhere to go). Also, the overlord, coordinator, router, and broker all show up in the services box – meaning the discovery between processes is also having the time of its life.
Now for the meat. The data servers. This is where I’m interested in the workers that it allocates automatically, and – importantly – the memory. This was tricky to get right when I did this manually. I had to work out a good historical memory size, then work out a good worker count that would divide up the remaining memory and not lead to OOMs all over the place during ingestion.
Let’s start there – the tasks and their memory. I used to have 4 workers on these data servers, and each worker would get 500m each.

The new script disagreed with both the count of the tasks, and with the memory per task. And it also disagreed with the historical and middleManager memory I’d calculated. On the left, the middleManager JVM settings and on the right the Historicals.

This is what the script decided upon - a much smaller middleManager (64m versus 128m), fewer worker tasks (2 versus 4) with a smaller memory footprint (256m versus 500m) and a smaller direct memory size (256m versus 500m), and a much smaller historical process (875m versus 2g) but with a greater max direct memory (1312m versus 500m).

I thought a chart might help me understand what’s going on:
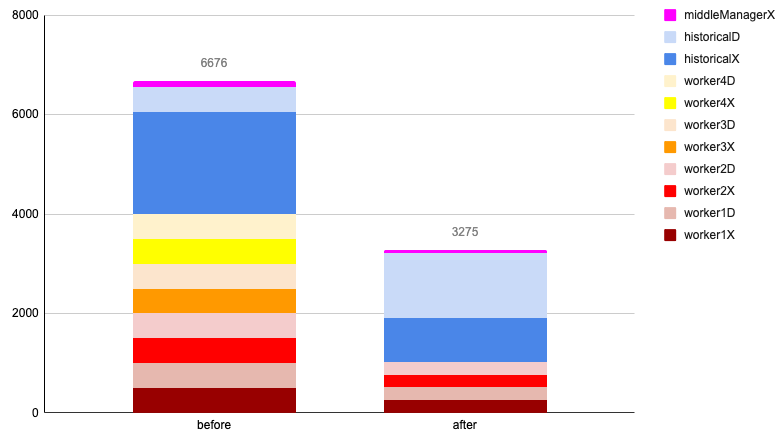
First, the script has fixed a stupid mistake I’d made.
(I told you this was coming...)
When all tasks were up under full load, my poor Pis would have had Java leaking from their USB ports. start-druid has reduced the task count, and it’s allocated a better amount of memory. With what it’s gained from there, it’s allocated more resources to the historical process.
This, together with the extra flexibility in the scripts to just start the processes I want to start triggered a thought...
"What happens if I dedicated one of my Raspberry Pis purely to ingestion?"
The answer? Well, people of the world, thanks to this awesome startup script, I can now test it. I just use the --compute flag, and I can create this pretty graph for your viewing pleasure:
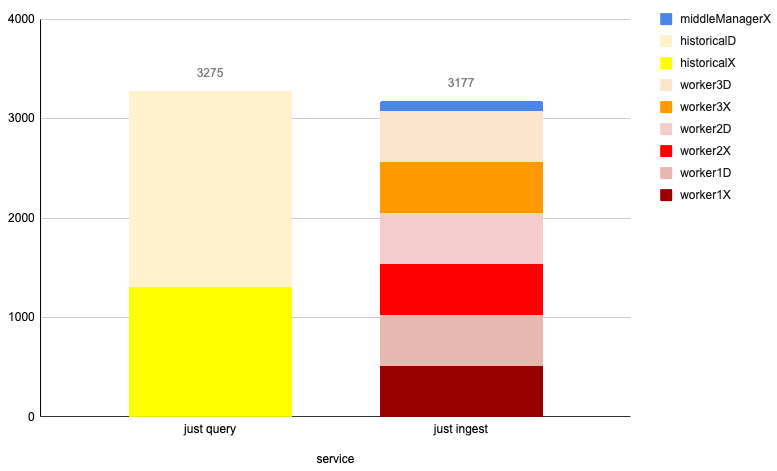
This information is invaluable – when you have a specific machine in mind, you can now see how Druid will allocate memory within that machine, considering the other available resources. This has prompted me to rethink how I might divide the microservices differently – not based on the idea of "I should just get a data server to fit into a single Raspberry Pi," but rather on how I want the memory and CPU to be utilized across all the resources available to me.
I’ve got 16 CPUs and 16GB RAM. How do I want to split that up as a whole (within the constraints of the PCBs, of course)?
Doesn’t it make more sense to let Druid “breathe” by using druid-start properly, and stop squishing things to make them fit? Druid’s got a shared-nothing, microservices architecture – I should be bloomin’ using it that way!
Why not have two “ingestion boxes” and two “historical query” boxes?
Or just one “historical query” box when I am mainly trying out different data models and partitioning schemes and all that jazz, but then use all of the Pis for Historical Query when I’m not doing any ingestion at all!
Thanks to this script, I realized I could run coordinator-overlord, zookeeper, broker, and router all on the same Pi! I freed up an entire machine. And thanks to the script, I'm less reliant on spreadsheets and can --compute to see what will happen. Now I just pick the processes I want, it calculates it using MAGIC (Python, actually), and then hey-presto – a brand new cluster configuration I can test out.
Conclusion
Thanks to the script, I now have a hybrid master/query Pi, three data query pis, and one ingestion pi.
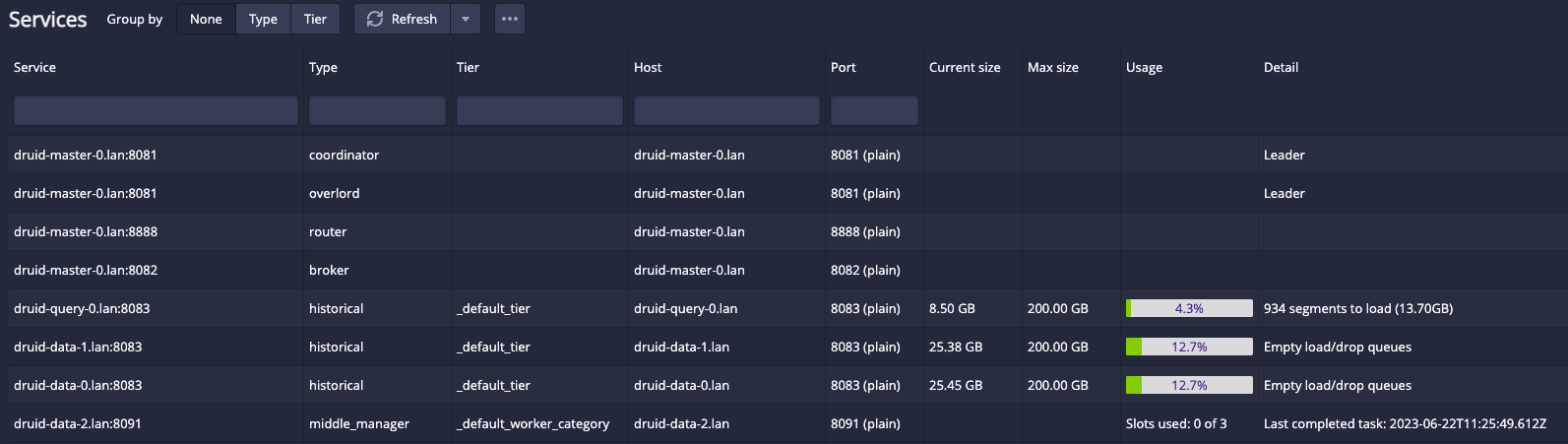
I’ve got rid of the silly error in my calculations that used to keep making ingestion crash
I’ve got way more flexibility in what I use my CPUs for depending on what I’m doing
My next upgrade is going to be less complicated - fewer individual configs to worry about.
I’m running Druid 26! WOOHOO!
All in all, I’m pretty chuffed with this script. Well done Druid project committers and contributors. Yet another little change to Druid that’s made a big difference!
Now then. Time to try out that UNNEST…



