





The idea behind the Apache Druid database is straightforward: it takes data, optimizes it, and uses a processing engine for fast GROUP BY operations. It's a cool, exciting OLAP database! To fully benefit from Druid, you need to explore the world of events. In this post, the key features of Apache Druid will guide you through how it handles event data.
All tables in Druid concern time.
Every row in a Druid table contains two elements:
A timestamp.
Dimensions.
Take a look in the data loader at the Koalas to the Max example data set (the same one used in the date and time functions Python notebook).

Evidence of devices (e.g. browser), visitors (geographic data), actions (event), and sessions (session, session length) are here.
The timestamp, __time, unifies all these dimensions, no matter the entity that those dimensions belong to. It communicates that, at the point this row was emitted, all this data was true.
Combined, every row in a Druid table records cause and effect. Queries on event tables like these help us do things like calculate entity state at a point in time (what browser was being used during session 5827 at 9am on Monday?) and to analyze behavior (how many visitors carried out event_type X?).
These queries all rely on the timestamp, and in response, Druid utilizes the event timestamp in significant ways.
Time drives ingestion.
When applied to real-time use cases, Druid users tend to want to inspect and analyze things that just happened more than they look at old behavior. To support that, this is what happens in Druid as events are ingested from sources like Amazon Kinesis and Apache Kafka.
As events are consumed, they are stored row-wise in memory, allowing Druid to keep up with the flow of data yet keep it queryable on arrival. As it accumulates, it is persisted to the local disk, optimizing it. Run a streaming ingestion on Druid, and these pieces of table data show up as “real-time segments” - they concern the most recently received data.
Each task hands off its data to long-term storage - the “deep store” - after a period of time. These events have started their ‘cooling off’ journey, keeping ingestion focused on high throughput, and putting the responsibility for query and management of this older data onto other processes.
Now Druid utilizes the event timestamp for data management for the first time. Retention rules are applied, proactively caching the data onto processes dedicated to interactive queries. These rules are built around the timestamp of the event.
Additional rules can cause Druid to automatically shift data onto hardware with a different profile. These rules also utilize the event timestamp.
Further rules might leave even older data uncached entirely, making it queryable only asynchronously via the asynchronous API (also known as MSQ).
And finally, very old data can be dropped entirely, again, configured using the event timestamp.
Time is central to data layout.
Events are necessarily repetitive. Not only are there multiple entities represented in a single event, but a given action might only change one of the dimension values. Run this query on the example data, and you see that a visitor has the same city throughout their session.
SELECT
"session",
COUNT(*) as "rows",
COUNT (DISTINCT "browser") as "browsers",
COUNT (DISTINCT "city") as "cities",
COUNT (DISTINCT "country") as "countries",
COUNT (DISTINCT "loaded_image") as "images"
FROM "example-koalas-fndatetime"
GROUP BY 1
ORDER BY 2 DESC
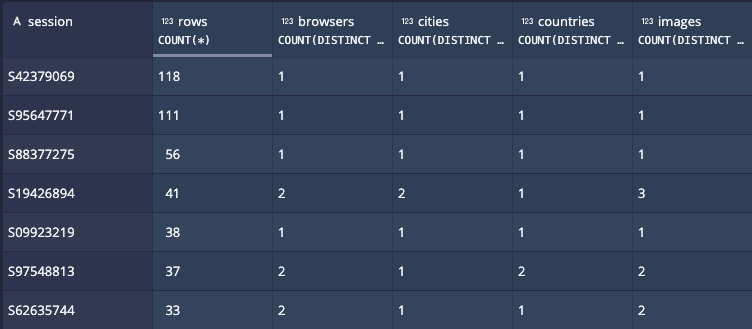
Storing the data like this would be unnecessarily heavy on storage, I/O, and compute power.
As Druid stores event data it applies dictionary encoding and bitmap indexing for storage efficiency, and to reduce overall read and processing times. Druid does this automatically for all ingestion (unless you turn it off) because this condition is so common in event data. That’s why there’s no explicit CREATE INDEX: it automatically takes incoming dimensions, columnarizes them, and applies indexes instead of the duplicative raw data.
The second part to Druid’s indexing is partitioning by time. A table is split up using the event timestamp into partitions. Rather than maintaining a global index across the entire table, which has proven to be expensive, Druid is therefore creating a per-column index that is local to a period of time.
Druid recognizes the episodic nature of behavior. Events tend to describe activity that spans a period of time, and which are themselves affected by time. The consequence is periodic cardinality. The images someone sees on a website don’t change a lot, but cities change hour-by-hour as visitors go on and offline across the globe.
This query “fakes” what Druid does on the example data, showing how many distinct values would exist in each index if you were to use a thirty-minute partition for the table data.
SELECT
TIME_FLOOR("__time",'PT30M') as "partition",
COUNT(DISTINCT "session") as "sessions",
COUNT(*) as "rows",
COUNT (DISTINCT "browser") as "browsers",
COUNT (DISTINCT "city") as "cities",
COUNT (DISTINCT "country") as "countries",
COUNT (DISTINCT "loaded_image") as "images"
FROM "example-koalas-fndatetime"
WHERE TIME_IN_INTERVAL("__time",'2019-08-25T14/PT3H')
GROUP BY 1
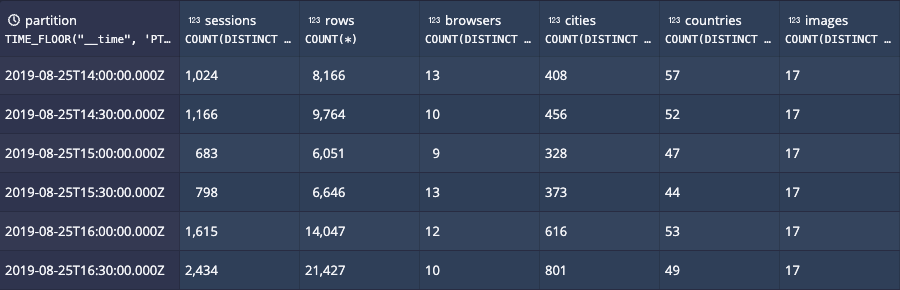
And time can be used to reduce the cardinality of events further!
When producers are noisy, repetitive, or generally creating too many events, Druid offers ingestion-time aggregation known as “rollup”. You configure rollup by giving Druid a “granularity” to reduce the event data to. It truncates the event timestamp to that granularity, and then carries out a GROUP BY to collapse the rows. You can also take some of the dimensions and turn them into aggregated versions.
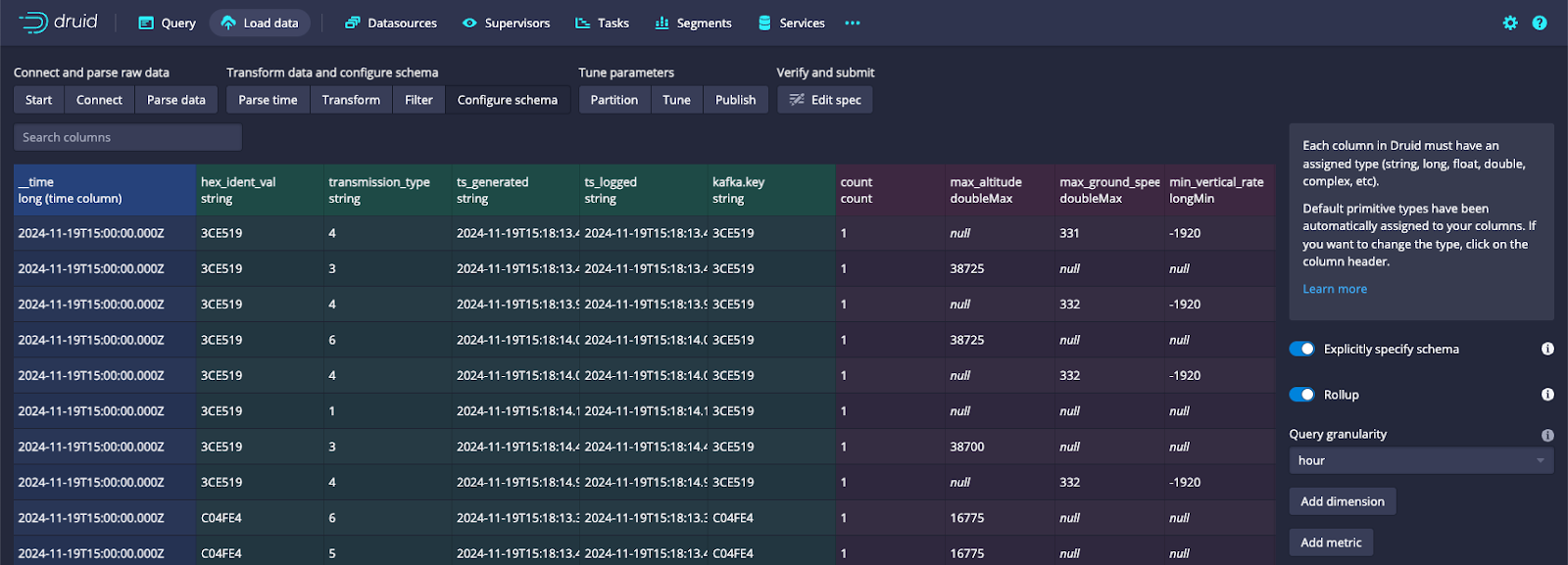
Rollup enabled on a sample dataset, showing the time truncation to the chosen query granularity (blue), entity dimensions (green), and aggregates to generate at ingestion time (red).
Rollup is very common in machine-generated event use cases like observability, IOT, and telecoms, driving down the size of tables while retaining enough granularity for queries.
At Druid Summit 2024, a new approach to data rollup was discussed - projections. Rather than choose between a table that is raw and a table that is rolled up, projections mean Druid can intelligently switch between different pre-computed aggregations depending on the query you’ve issued. More to come on this as time goes on!
Let’s not forget, though, that events might arrive late or out of order. When this happens, those time partitions - and the indexes with them - become overhead. Or perhaps the older the data is, the fewer segments we believe should be present. To maintain data layout, Druid offers compaction, putting the right events into the right partitions, and allowing us to change the granularity of partitions. Compaction configuration uses event timestamps, including what period of events that should be processed, and how long each new aggregated partition should cover (“segment granularity”).
Events might also have different schemas over time. The producers themselves might change (a new product line of sensors, for example), or the stream might contain multiple readings for the same real-world entities. Both schema evolution and - more recently - schema autodetection have been built in recognition that time impacts the source data itself - not just what you do with it.
Time optimizes query execution.
For some time, Druid’s been known for extremely fast query execution. Nowadays it has multiple engines for lots of different query patterns.
Let’s focus on the engine it’s best known for: the interactive query API.
The planning for interactive queries breaks down a SELECT into parts and executes each one in parallel. The planning effort is firmly rooted in event timestamps.
Take this query:
SELECT
TIME_FLOOR("__time",'PT1H') as "period",
REGEXP_REPLACE("loaded_image",'^(([^:/?#]+):)?(//([^/?#]*))?([^?#]*)(\?([^#]*))?(#(.*))?','$5') AS "path",
MAX("session_length") as "longest_session"
FROM "example-koalas-fndatetime"
WHERE TIME_IN_INTERVAL ("__time",'2019-08-25/PT2H')
GROUP BY 1, 2
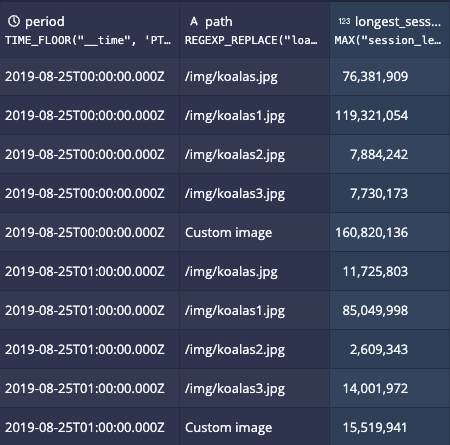
Imagine that tables are partitioned into hourly partitions based on the event timestamp. Queries for the first hour concern one segment, while the second hour concerns another. Druid executes the query in parallel, one thread for each segment - so one thread per hour of data.
The way parallelisation works unlocks another key use case for Druid - episodic comparison. When someone wants to compare session length today versus session length a month ago, the segments for each period are identified, work broken down, and then executed in parallel - no full table scan.
The caches in Druid are also closely related to the event timestamp.
Retention rules control caching for the interactive API. They tell Druid what segments to cache onto which nodes. Each rule applies to a period of event time. One of the configurable options is a replication factor. This helps not just with availability, but with controlling the number of nodes that get a copy of the periods of time covered by your table, and therefore control over the maximum level of parallelism possible when queries run.
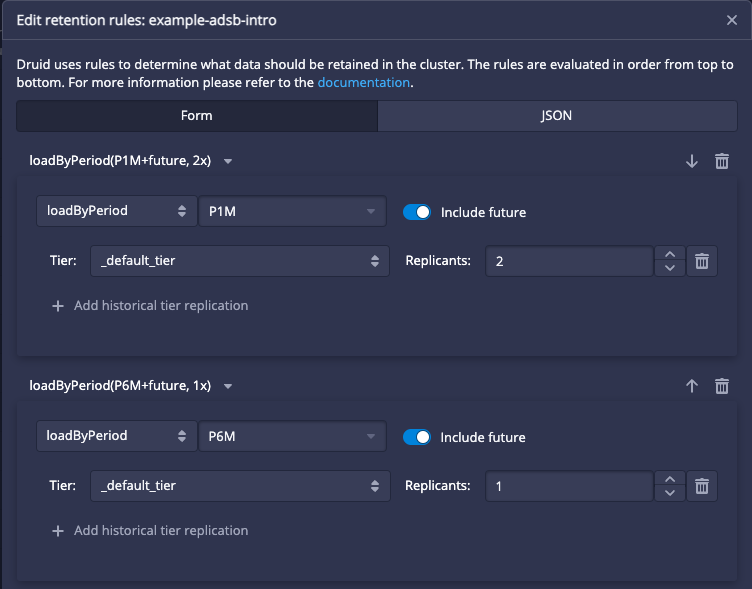
An example of retention rules for a table. The first month has two replicas, the next five months have one.
After the rules have been run and the data has been cached, segments are read from the local cache at query time into local memory. This gives a local in-memory cache. Most frequently accessed intervals of events, therefore, are more likely to be served from memory, rather than via local disk, because the related segments will be in the memory-mapped area. The effectiveness of the in-memory cache is directly related to the frequency with which your queries hit the same period of time in the data.
In 2021, a new query execution engine was conceived. For data where a database based on separation of storage and compute will do, even older table data can be removed from interactive query processes altogether, and instead queried directly using the asynchronous API. Consequently, the “multi-stage query” (MSQ) engine enables processing in batch, much closer to ETL / ELT workloads. Able to run operations asynchronously, the MSQ engine operates on table data directly from long-term (“deep”) storage, enabling it to cover real-time segments if needed. In time, external tables became a fully supported element of MSQ-executed queries, enabling Druid to address Apache Iceberg, Deltalake, and other sources as part of the processing. Many more events can therefore be processed by Druid, as well as entity data stored in external systems.
More complex queries have continued to surface in the community. And in response, in 2024, Gian Merlino introduced the evolution of the interactive query engine: Dart. Engineers envision a single query engine with multiple profiles, enabling data engineers to run application-powering interactive queries (more like real-time) as well as more traditional reporting and business intelligence queries (more like batch) through one API.
Conclusion
Time is central to events, and it is central to Druid.
The event timestamp not only unites data about entities that are involved in activity into a single, immutable record of an action taken, it is the foundation of how Druid works.
Druid’s combination of time-based indexing, time-based data management, and time-based query execution has created, as Gian Merlino described it at Druid Summit 2024, “the ideal query engine for the event-oriented system”.